
RoboEvalfor researchers & developers
Test your model against real-world workflows.
RoboEval evaluates your VLA, video-action, or world model in high-fidelity simulation, then on real robots — hundreds of episodes under real lighting, real placement error, real failure. With diagnostics for exactly where it breaks.
Benchmarks don't predict reliability.
A model that scores 95% in simulation drops to 60% in production. A lighting change costs 5–10% accuracy. Open-weight VLAs that match proprietary models on public leaderboards collapse on zero-shot real-world tasks.
Two phases. Sim to real.
Every model runs the same pipeline — the one that separates simulation performance from real-world reliability.
Simulation
Your model runs hundreds of episodes across scenarios in high-fidelity physics simulation, scored on task completion, safety, and efficiency. Simulation is fast, repeatable, and cheap, so we test broadly and filter to the top performers without tying up a single robot.
The scenes aren’t toy environments. SceneForge reconstructs real deployment sites from video into photoreal, physics-ready simulation — so a model is tested against the place it will actually run.
Real-world
Top performers move to physical robots in our lab, under the conditions that actually break models: variable lighting, imperfect object placement, environmental noise. Multiple robot form factors and built-in failure diagnostics that surface when and why a model breaks down — not just whether it passed.
What you get.
Per-episode video
Watch every rollout. Replay the exact episode a model failed.
Failure diagnostics
When and why a model breaks — not just pass/fail.
Multi-scene evaluation
One model, many scenes, per-scene success rates.
A/B comparison
Two models, side by side, identical conditions.
Public leaderboard
Ranked on real-world-predictive evals.
Open by default
Bring a model from the open ML ecosystem — OpenVLA, π0, GR00T, RT-2, and more.
The first benchmark
WarehouseBench
WarehouseBench is our first evaluation suite — bi-manual robot arms running packing, kitting, and order fulfillment, the workflows real warehouses run. v1 scores the metrics that decide whether a deployment works, not just whether a task completed.
Success rate
did the task complete.
Containment accuracy
did items land where they belong.
Closure quality
is the package sealed correctly.
Post-action stability
does it stay put after the arm lets go.
Next: Physical Tool Use — extending the evaluation surface to adjacent deployment categories.
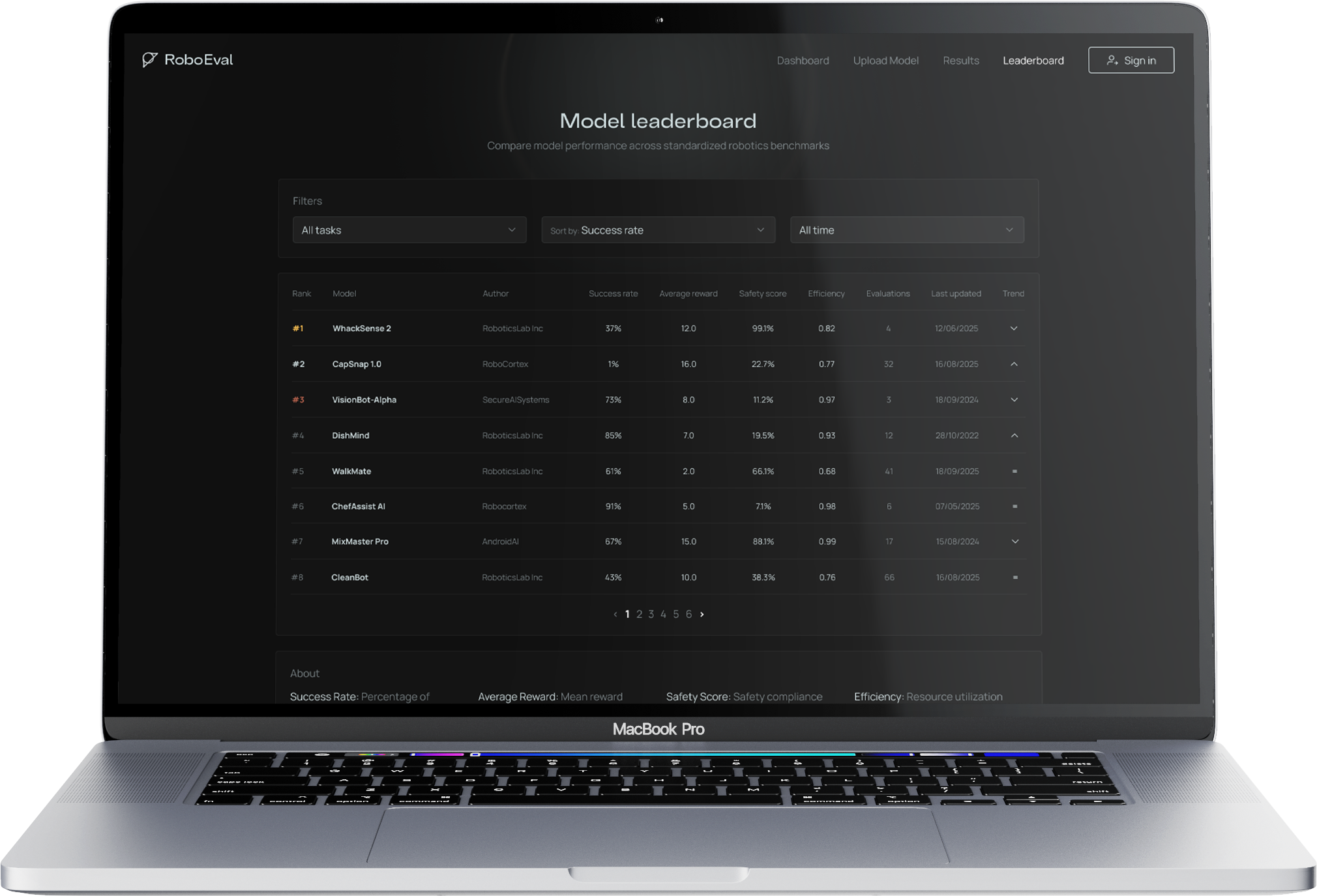
The leaderboard.
A public ranking of frontier open models on evaluations built to predict real-world reliability — not simulation scores. See how the field actually stacks up. Then put your model on the board.
How does your model compare?
RoboEval is in private access. Sign in with GitHub, request access, and we’ll get you onboarded.
Built for the open ML ecosystem.